Troubleshooting a MongoDB Performance Issue
UPDATE (2018-06-28): I actually sent a link to this article to the author of the previous blog post and in her reply she indicates that the improvements to cache management and checkpoint areas were more likely to have improved my situation. Just wanted to call out how approachable the MongoDB team is even with these one-off type issues :). Thanks Sue!
UPDATE (2018-06-21): As we were running MongoDB 3.0.15 while all these issues were going on it’s entirely possible that the optimizations made to the write-ahead log of WiredTiger may have also contributed to this improvement in performance :)
The following is an edited excerpt from an email I sent out internally about an intermittent performance issue we’ve been experiencing for several years now. The daily processing challenges we’ve been experiencing revolved around running server-side javascript in order to produce daily reports. As our data ingestion rates rose and our data processing needs climbed, our server performance continued to degrade. This would occur regardless of the size of the VMs we would spin up.
Postmortem
Our MongoDB cluster is configured with three (3) servers: 1x primary (write-enabled) and 2x secondaries (read-only). These are running on Azure DS14v2 VMs with 8TB of storage (8x 1TB striped via LVM as these were the largest premium SSD-based data disks available at the time).
Aside from the servers being scaled up periodically, this configuration has been constant since the inception of the product.
The only major upgrade came in the form of a migration from 2.6 to 3.0 in 2015. At the time this was a major shift as it required rewriting a number of the underlying system scripts as well as introducing LRS-based storage to try and squeeze some additional performance out of the disks. Why optimize for IOPS? Because the reporting platform was designed to copy a lot of data back and forth in order to generate reports segmented by dimension (“Group”, “Company”, “Country”, “State”, “City”).
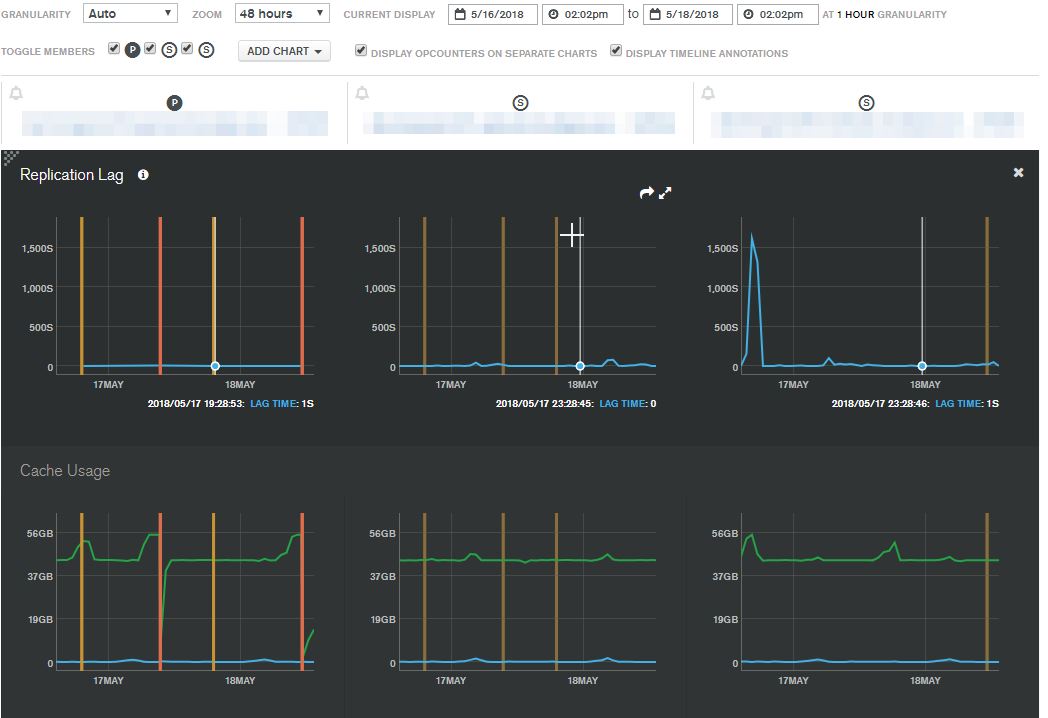
This chart (48 hours sampled from 1 week ago) shows Cache Usage spiking and Replication Lag spiking. The cache spikes occur as new writes trigger index activity, which invalidates (dirties) cached memory and causes cache eviction.
This slows down the speed at which the secondaries can request data from the primary, which spikes the lag. When the secondaries request more data, it would lock up the primary, which in turn affected the primary server’s ability to ingest new content and write it to disk. The read/write buffers back up and new write requests are throttled.
Note — As of MongoDB 4.0, non-blocking secondary reads have been added to address these types of latency issues.
This type of cascading failure was almost exclusively seen when a large batch process was being run in the morning directly on the primary mongod instance in the mornings..
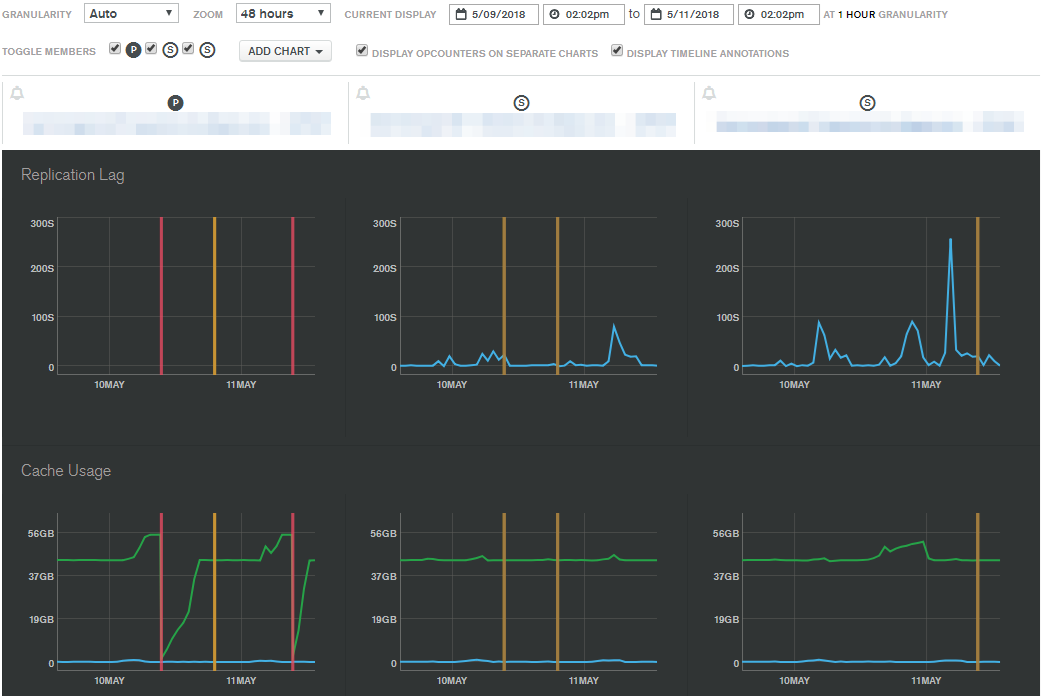
This chart (48 hours sampled from 2 weeks ago) shows similar behaviour. The vertical lines show points at which we were forced to restart instances or cycle the primary server in order to recover resources.
You’ll notice that cache usage hits a certain point on the primary (left) server after which we have to kill the instance. The replication lag on the secondaries is also inconsistent, which would lead us to believe that the consumption rates from the primary are being affected by either network performance or disk performance.
In the absence of dedicated DevOps, DBAs or Infrastructure Engineers, the development teams have spent a significant amount of time learning to tune and troubleshoot this installation. Due to lack of specialization though occasionally issues may be misdiagnosed.
We completed a significant upgrade on Tuesday that brings our cluster up to mongodb-server 3.4.15 (from 3.0.15). The 3.0 series was first introduced in March 2015, with an end of life of February 2018. As no further security updates are being released, we’ve been coordinating tests with the product development teams for the past 12 months in order to prepare for a major upgrade.
This involved the deprecation of client-side javascript calls, as well as rewriting several map/reduce operations as aggregation pipelines to ensure when the transition happened there was no sudden outage.
Now that we’ve been running 3.4 in production for a few days I checked the same 48 hour sample and found something interesting …
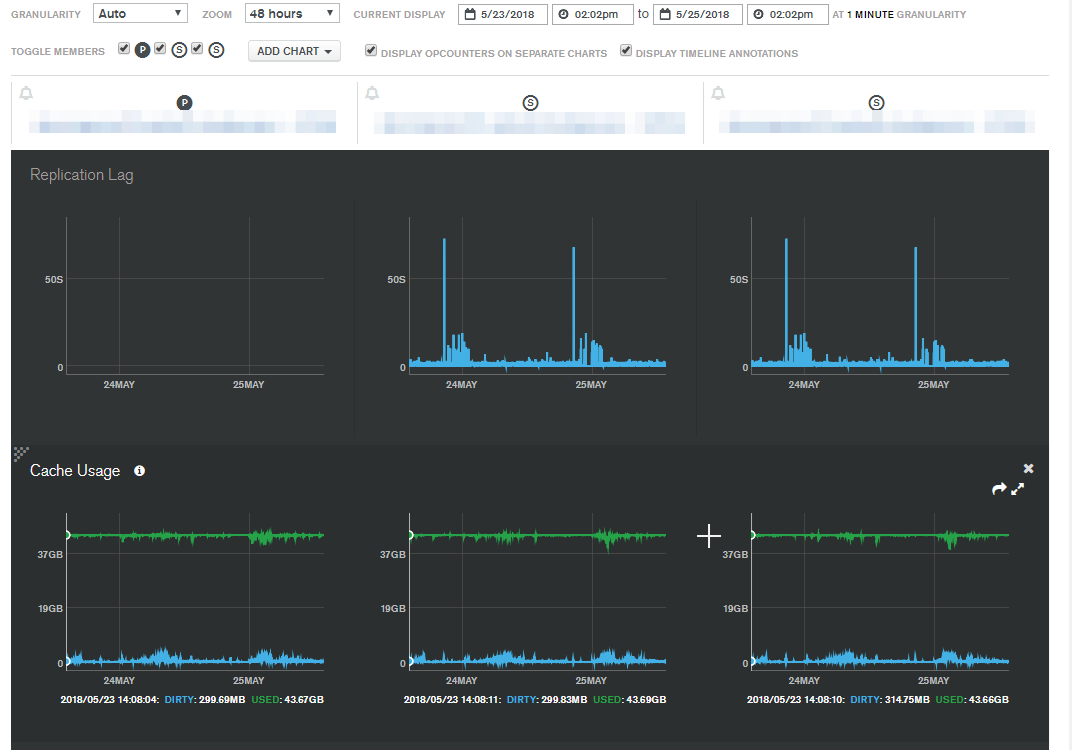
The cache usage has remained steady since we turned the instances on. The replication lag also hasn’t gone much higher than a minute in the past few days (this could creep up to over an hour in the past!).
These samples include report generation for all products as well, so they represent the same load. We’ll have to continue to monitor this, but the initial results seem to show that a lot of the pain we’ve been suffering through may have stemmed from outdated software.
The way the review report is generated is still extremely inefficient, but if we continue seeing results like this for the foreseeable future then the urgency of redesigning that product drops and can be properly managed.
Here are some lessons we learned as a result of this investigation:
Measure Everything — Without proper telemetry in place, not only is it difficult to identify negative trends, but it’s almost impossible to showcase the success of any change or action.
Understand Your Tech — Whether you’re using hosted, provisioned, on-premise, containerized, PAAS or some other solution as part of the application architecture, make sure you really understand how to use it, and how to support it. When MongoDB was introduced to the project it was done so to fill a specific need. Once that need was filled, resourcing discussions surrounding maintainability and support should likely have been prioritized.
Document Everything — As discoveries are made, write them down and share them. Knowledge sharing is even more important when you’re dealing with issues that go beyond the standard requirements of “application development”.
Ask For Help — When it becomes necessary to step outside your comfort zone to solve a problem, a fresh perspective can be welcome.
Hopefully this journey benefits someone else in a similar situation.
Comments powered by Disqus.