Optimizing MongoDB Compound Indexes - The "Equality - Sort - Range" (ESR) Rule
UPDATE
DOCS-11790 has finally been implemented and as a result the MongoDB public documentation now contains a tutorial for The ESR (Equality, Sort, Range) Rule!
Working in Technical Services at MongoDB I find that time and again customers need assistance understanding why the operations they’ve created indexes for may not be performing optimally. When providing supplementary documentation, the go-to article is “Optimizing MongoDB Compound Indexes” by MongoDB’s A. Jesse Jiryu Davis.
I’ve presented this topic now at MongoDB.local Toronto 2019 (in “Tips and Tricks for Effective Indexing”) and at MongoDB World 2019 (in “The Sights (and Smells) of a Bad Query”). My colleague Chris Harris has also covered this topic at MongoDB World 2019 (in “Tips and Tricks++ for Querying and Indexing MongoDB”) and again at the MongoDB.local Houston 2019, for which a video is available.
Though we have Jesse’s excellent (and still applicable and valid) article from 2012, I wanted to take this opportunity to collect some thoughts on this topic based on his work and previous presentations.
The ESR “Rule”
The ordering of index keys in a compound index is critically important, and the ESR “Rule” can be used as a rule of thumb to identify the optimal order in most cases.
The reason we are putting “Rule” in quotations is because, though the guidance is applicable in most cases, there are exceptions to be aware of. These exceptions are covered in greater detail in my in “Tips and Tricks for Effective Indexing” presentation.
The “Rules”
(1) Equality predicates should be placed first
An equality predicate is any filter condition that is attempting to match a value exactly. For example:
1
2
3
find({ x: 123 })
find({ x: { $eq: 123 } })
aggregate([ { $match:{ "x.y": 123 } } ])
These filters will be tightly bound when seen in the indexBounds of an Explain Plan:
1
2
3
4
5
"indexBounds" : {
"x" : [
"[123.0, 123.0]"
]
}
Note that multiple equality predicates do not have to be ordered from most selective to least selective. This guidance has been provided in the past however it is erroneous due to the nature of B-Tree indexes and how in leaf pages, a B-Tree will store combinations of all field’s values. As such, there is exactly the same number of combinations regardless of key order.
(2) Sort operation follows Equality predicates Sort fields represent the entire requested sort operation and determine the ordering of results. For example:
1
2
3
find().sort({ a: 1 })
find().sort({ b: -1, a: 1 })
aggregate([ { $sort: { b: 1 } } ])
The index bounds for the sort fields will be unbounded (assuming the fields aren’t also filtered on) as it requires the entire key range to be scanned to satisfy the sort requirements:
1
2
3
4
5
6
7
8
"indexBounds" : {
"b" : [
"[MaxKey, MinKey]"
],
"a" : [
"[MinKey, MaxKey]"
]
}
(3) Range predicates follow Equality and Sort fields
Range predicates are filters that may scan multiple keys as they are not testing for an exact match. For example:
1
2
3
find({ z: { $gte: 5} })
find({ z: { $lt: 10 } })
find({ z: { $ne: null } })
The range predicates will be loosely bounded as a subset of the key range will need to be scanned to satisfy the filter requirements:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
"indexBounds" : {
"z" : [
"[5.0, inf.0]"
]
}
"indexBounds" : {
"z" : [
"[-inf.0, 10.0)"
]
}
"indexBounds" : {
"z" : [
"[MinKey, undefined)",
"(null, MaxKey]"
]
}
These three tenets of the “rule” have to do with how a query will traverse an index to identify the keys that match the query’s filter and sort criteria.
Setup
For the duration of this section we’ll be working with the following data to help illustrate the various guiding principles:
1
2
3
4
5
{ name: "Shakir", location: "Ottawa", region: "AMER", joined: 2015 }
{ name: "Chris", location: "Austin", region: "AMER", joined: 2016 }
{ name: "III", location: "Sydney", region: "APAC", joined: 2016 }
{ name: "Miguel", location: "Barcelona", region: "EMEA", joined: 2017 }
{ name: "Alex", location: "Toronto", region: "AMER", joined: 2018 }
We will also be examining simplified (filtered) Explain Plan’s executionStats from each operation using a variation of the following command:
1
find({ ... }).sort({ ... }).explain("executionStats").executionStats
(E) Equality First
When creating queries that ensure selectivity, we learn that “selectivity” is the ability of a query to narrow results using the index. Effective indexes are more selective and allow MongoDB to use the index for a larger portion of the work associated with fulfilling the query.
Equality fields should always form the prefix for the index to ensure selectivity.
(E → S) Equality before Sort
Placing Sort predicates after sequential Equality keys allow for the index to:
- Provide a non-blocking sort.
- Minimize the amount of scanning required.
To better understand why this is we will begin with the following example:
1
2
3
// operation
createIndex({ name: 1, region: 1 })
find({ region: "AMER" }).sort({ name: 1 })
With the Sort predicate first, the full key range would have to be scanned prior to the more selective equality filter being applied:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// execution stats
"nReturned" : 3.0,
"totalKeysExamined" : 5.0,
"totalDocsExamined" : 5.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"name" : [
"[MinKey, MaxKey]"
],
"region" : [
"[MinKey, MaxKey]"
]
},
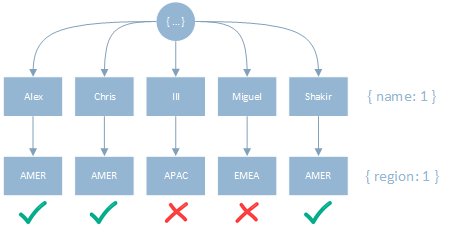
With this index, all 5 keys have to be scanned (totalKeysExamined) to identify the 3 matching documents (nReturned).
1
2
3
// operation
createIndex({ region: 1, name: 1 })
find({ region: "AMER" }).sort({ name: 1 })
With the Equality predict first, the tight bounds allow less keys to be scanned to satisfy the filter criteria:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// execution stats
"nReturned" : 3.0,
"totalKeysExamined" : 3.0,
"totalDocsExamined" : 3.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"region" : [
"[\"AMER\", \"AMER\"]"
],
"name" : [
"[MinKey, MaxKey]"
]
},
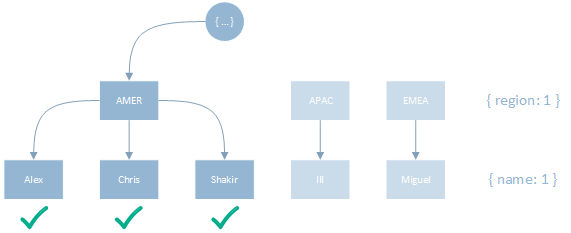
(E → R) Equality before Range
Though Range predicates scan a subset of keys (unlike Sort predicates), they should still be placed after Equality predicates to ensure the key ordering is optimized for selectivity.
1
2
3
// operation
createIndex({ joined: 1, region: 1 })
find({ region: "AMER", joined: { $gt: 2015 } })
Having the Range before the Equality predicate causes more keys to be scanned to identify the matching documents:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// execution stats
"nReturned" : 2.0,
"totalKeysExamined" : 4.0,
"totalDocsExamined" : 2.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"joined" : [
"(2015.0, inf.0]"
],
"region" : [
"[\"AMER\", \"AMER\"]"
]
},
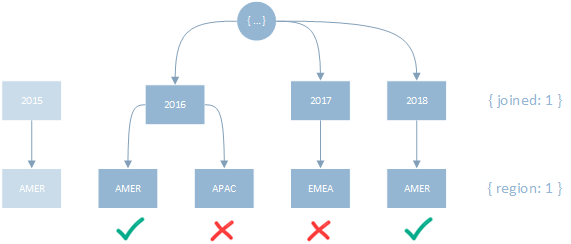
In this example, 4 keys had to be scanned to identify the 2 matches. Changing the order of the keys to place the Equality predicate first will reduce the amount of scanning required:
1
2
3
// operation
createIndex({ region: 1, joined: 1 })
find({ region: "AMER", joined: { $gt: 2015 } })
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// execution stats
"nReturned" : 2.0,
"totalKeysExamined" : 2.0,
"totalDocsExamined" : 2.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"region" : [
"[\"AMER\", \"AMER\"]"
],
"joined" : [
"(2015.0, inf.0]"
]
},
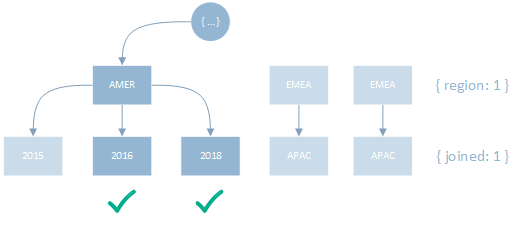
After placing the Equality predicate before the Range predicate, only the number of keys necessary to satisfy the filter criteria are scanned.
(S → R) Sort before Range
Having a Range predicate before the Sort can result in a Blocking (In Memory) Sort being performed as the index cannot be used to satisfy the sort criteria.
1
2
3
// operation
createIndex({ joined: 1, region: 1 })
find({ joined: { $gt: 2015 } }).sort({ region: 1 })
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// execution stats
"nReturned" : 4.0,
"totalKeysExamined" : 4.0,
"totalDocsExamined" : 4.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "SORT",
...
"sortPattern" : {
"region" : 1.0
},
"memUsage" : 136.0,
"memLimit" : 33554432.0,
"inputStage" : {
"stage" : "SORT_KEY_GENERATOR",
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"joined" : [
"(2015.0, inf.0]"
],
"region" : [
"[MinKey, MaxKey]"
]
},
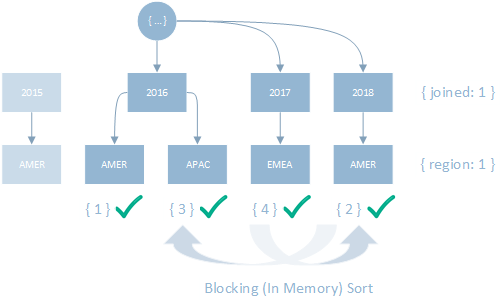
In this example, the filter was able to use the index selectively to identify the 4 keys needed to satisfy the query, however the results are not known to be in order. This results in the identified keys being sorted in memory prior to be returned to the calling stage in the execution plan.
By moving the Sort predicate before the Range predicate however, even though more keys may need to be scanned the keys will be returned correctly ordered.
1
2
3
// operation
createIndex({ region: 1, joined: 1 })
find({ joined: { $gt: 2015 } }).sort({ region: 1 })
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// execution stats
"nReturned" : 4.0,
"totalKeysExamined" : 5.0,
"totalDocsExamined" : 5.0,
"executionStages" : {
...
"inputStage" : {
"stage" : "IXSCAN",
...
"indexBounds" : {
"region" : [
"[MinKey, MaxKey]"
],
"joined" : [
"[MinKey, MaxKey]"
]
},
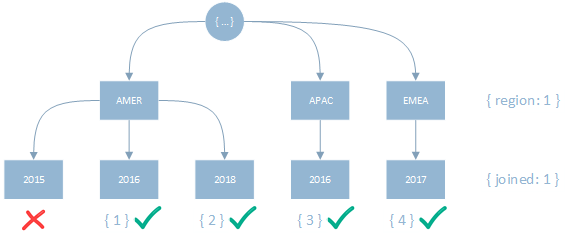
Though this method requires scanning additional keys the lack of a blocking sort will generally be far more efficient/performant.
I hope that the ESR “Rule” helps you optimize your MongoDB indexes and improve your query performance. If you have questions, feel free to hit me up in the comments, or check out the MongoDB Developer Community forums.
If you need more timely assistance, consider MongoDB’s Atlas Developer Support or Enterprise Support.
Cheers, and happy optimizing!
Comments powered by Disqus.