Ensuring a MongoDB Replica Set Member's Priority Takeover Succeeds
High availability implies a system has been designed for durability, redundancy, and automatic failover such that the applications supported by the system can operate continuously and without downtime for a long period of time. MongoDB replica sets support high availability when deployed according to the documented best practices.
The priority settings of replica set members affect both the timing and the outcome of elections for primary. Higher-priority members are more likely to call elections, and are more likely to win. The MongoDB documentation outlines a procedure to Force a Member to be Primary by Setting its Priority High, which can be easily demonstrated by changing the replica set’s priorities through a replSetReconfig command.
In this article we will demonstrate how to utilize replica set member priority to ensure a given node assumes the primary role under ideal circumstances, as well as under load (when there is consistent replication lag).
Initial Setup
1
2
3
4
5
6
# setup a PSS replica set
mlaunch init --replicaset --nodes 3 --binarypath $(m bin 4.2.17-ent)
# using the mongo shell reconfigure the set
# with the 3rd node having a priority of 10
mongo "mongodb://localhost:27017/?replicaset=replset" --quiet \
--eval "c = rs.conf(); c.members[2].priority = 10; rs.reconfig(c)"
To setup the replica set the m version manager is used along with mtools. Once the replica set is reconfigured via the mongo shell, checking the logs for the rs3 node that should now be PRIMARY should show the results of the priority takeover:
1
tail -n 1000 data/replset/rs3/mongod.log | grep -E "(ELECTION|REPL)"
2021-10-06T06:50:38.730-0400 I REPL [replexec-2] New replica set config in use: { _id: "replset", version: 2, protocolVersion: 1, writeConcernMajorityJournalDefault: true, members: [ { _id: 0, host: "localhost:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 }, { _id: 1, host: "localhost:27018", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 }, { _id: 2, host: "localhost:27019", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 10.0, tags: {}, slaveDelay: 0, votes: 1 } ], settings: { chainingAllowed: true, heartbeatIntervalMillis: 2000, heartbeatTimeoutSecs: 10, electionTimeoutMillis: 10000, catchUpTimeoutMillis: -1, catchUpTakeoverDelayMillis: 30000, getLastErrorModes: {}, getLastErrorDefaults: { w: 1, wtimeout: 0 }, replicaSetId: ObjectId('615d7f403cd84ab3e708fdea') } }
2021-10-06T06:50:38.730-0400 I REPL [replexec-2] This node is localhost:27019 in the config
2021-10-06T06:50:38.737-0400 I ELECTION [replexec-3] Scheduling priority takeover at 2021-10-06T06:50:48.909-0400
2021-10-06T06:50:48.911-0400 I REPL [replexec-4] Canceling priority takeover callback
2021-10-06T06:50:48.911-0400 I ELECTION [replexec-4] Starting an election for a priority takeover
2021-10-06T06:50:48.911-0400 I ELECTION [replexec-4] conducting a dry run election to see if we could be elected. current term: 1
2021-10-06T06:50:48.912-0400 I REPL [replexec-4] Scheduling remote command request for vote request: RemoteCommand 183 -- target:localhost:27017 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: true, term: 1, candidateIndex: 2, configVersion: 2, lastCommittedOp: { ts: Timestamp(1633517438, 1), t: 1 } }
2021-10-06T06:50:48.912-0400 I REPL [replexec-4] Scheduling remote command request for vote request: RemoteCommand 184 -- target:localhost:27018 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: true, term: 1, candidateIndex: 2, configVersion: 2, lastCommittedOp: { ts: Timestamp(1633517438, 1), t: 1 } }
2021-10-06T06:50:48.912-0400 I ELECTION [replexec-9] VoteRequester(term 1 dry run) received a yes vote from localhost:27017; response message: { term: 1, voteGranted: true, reason: "", ok: 1.0, $clusterTime: { clusterTime: Timestamp(1633517438, 1), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, operationTime: Timestamp(1633517438, 1) }
2021-10-06T06:50:48.912-0400 I ELECTION [replexec-5] dry election run succeeded, running for election in term 2
2021-10-06T06:50:48.941-0400 I REPL [replexec-5] Scheduling remote command request for vote request: RemoteCommand 185 -- target:localhost:27017 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: false, term: 2, candidateIndex: 2, configVersion: 2, lastCommittedOp: { ts: Timestamp(1633517438, 1), t: 1 } }
2021-10-06T06:50:48.942-0400 I REPL [replexec-5] Scheduling remote command request for vote request: RemoteCommand 186 -- target:localhost:27018 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: false, term: 2, candidateIndex: 2, configVersion: 2, lastCommittedOp: { ts: Timestamp(1633517438, 1), t: 1 } }
2021-10-06T06:50:48.957-0400 I ELECTION [replexec-1] VoteRequester(term 2) received a yes vote from localhost:27018; response message: { term: 2, voteGranted: true, reason: "", ok: 1.0, $clusterTime: { clusterTime: Timestamp(1633517438, 1), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, operationTime: Timestamp(1633517438, 1) }
2021-10-06T06:50:48.960-0400 I ELECTION [replexec-8] election succeeded, assuming primary role in term 2
2021-10-06T06:50:48.961-0400 I REPL [replexec-8] transition to PRIMARY from SECONDARY
The above example will work every time on a local cluster with no traffic and no lag. What happens when we start applying some traffic to this cluster using a process that supports Retryable Writes?
Retryable Workload
Retryable writes allow MongoDB drivers to automatically retry certain write operations a single time if they encounter network errors, or if they cannot find a healthy primary in the replica sets or sharded cluster. Based on this guarantee our assumption would be that the write workload should continue uninterrupted:
1
2
3
curl -s https://gist.githubusercontent.com/alexbevi/955c6675337107e16d637233f865b1e3/raw/cca0390f6c30898140cc55490930b80c5cad527b/template.json | \
mgeneratejs -n 5000000 | \
mongoimport --uri "mongodb://localhost:27017/test?replicaSet=replset&w=majority&retryWrites=true" --collection data --numInsertionWorkers 1 --drop
The mongoimport command, along with mgeneratejs are used to generate data and write the results to the test.data namespace. Note the version of mongoimport used is > 100.2.1 as this ensures retryable writes are supported (per TOOLS-2745).
Assuming the retryable writes guarantee is accurate, performing another replSetReconfig to shift the highest priority to another node should allow the election to occur without interrupting the mongoimport workload.
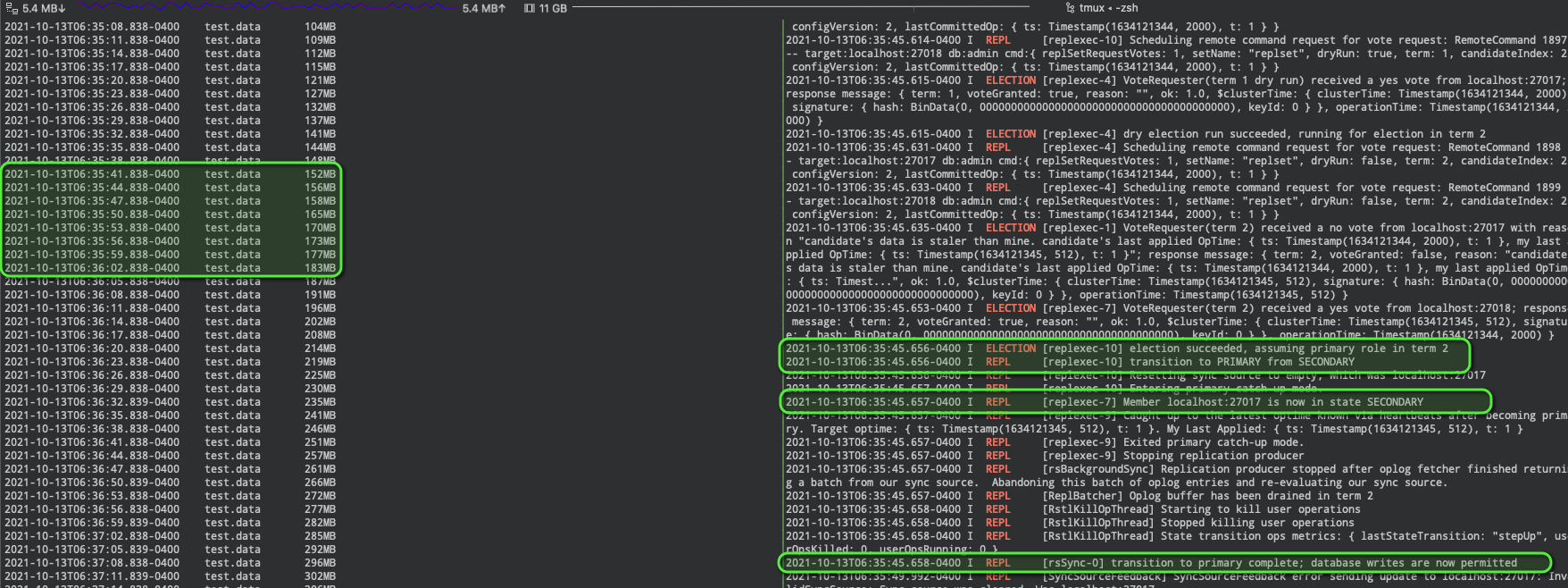
Using tmux to manage multiple terminals (as seen in the screenshot above), the mongoimport (left panel) continues to import data while the election is triggered and completes (per the logs of the new PRIMARY in the right panel).
Retryable Workload with an Oplog Delay
In the above example the mongoimport workload was able to successfully continue with retryable writes enabled. Retryable writes are not a requirement in this scenario however (per the Retryable Writes Specification) having this feature enabled will ensure server errors such as NotWritablePrimary, NotPrimaryNoSecondaryOk, NotPrimaryOrSecondary, PrimarySteppedDown will be retried.
Next we want to run the same test but with an artificial lag introduced to the node that is expected to step up as primary due to priority.
Simulating an Oplog Delay
Replication lag is a delay between an operation on the primary and the application of that operation from the oplog to the secondary (see “Check Replication Lag”). Our test above was able to easily complete a priority takeover and election as the nodes are all on the same host (localhost) and there should be virtually no delay between writes and replicated operations.
The following script uses the fsync and fsyncUnlock commands to block a target node from performing writes. By doing this in a timed fashion we can simulate replication lag on a secondary as the node cannot apply writes from the oplog while it is locked.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// file: secondaryDelay.js
//
// the host:port of the node to connect to and lock/unlock
const NODE = "localhost:27019";
// how long to block operations (in milliseconds)
const DELAY = 3500;
function delaySecondary(c, t) {
c.getDB("test").fsyncLock();
sleep(t);
c.getDB("test").fsyncUnlock();
// print secondary replication info to show lag
print(db.printSecondaryReplicationInfo());
}
var c = new Mongo(NODE);
while(true) {
delaySecondary(c, DELAY);
sleep(100);
}
When the secondaryDelay.js script is run and the replica set reconfiguration is performed, the priority takeover should now fail.
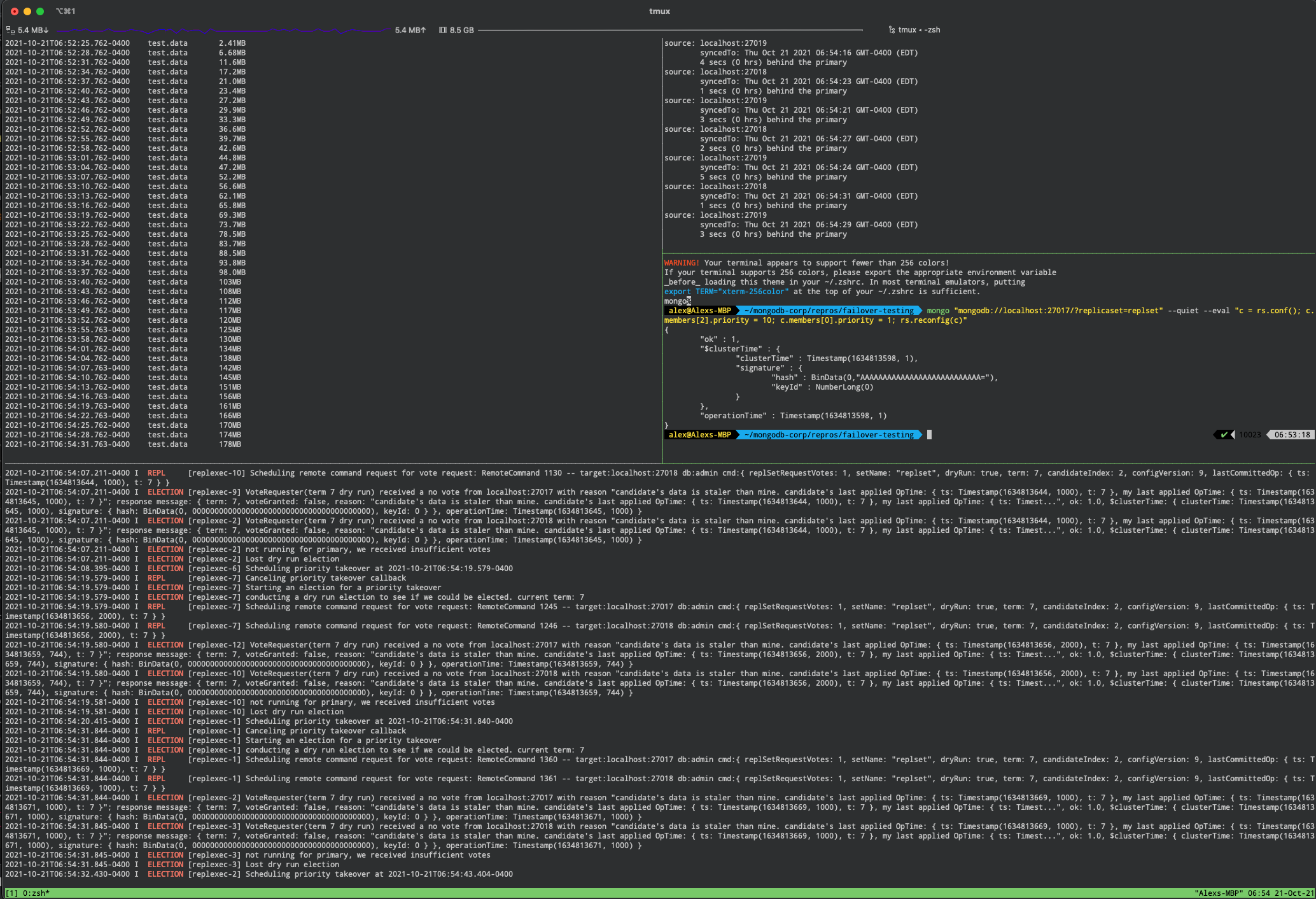
To simulate the failure, the following commands were running in tmux windows:
mongoimportmongo --quiet secondaryDelay.jsmongo "mongodb://localhost:27017/?replicaset=replset" --quiet --eval "c = rs.conf(); c.members[0].priority = 1; c.members[2].priority = 10; rs.reconfig(c)"tail -n 1000 data/replset/rs3/mongod.log | grep -E "(ELECTION|REPL)"
2021-10-21T06:53:56.388-0400 I ELECTION [replexec-12] Scheduling priority takeover at 2021-10-21T06:54:07.210-0400
2021-10-21T06:54:07.210-0400 I REPL [replexec-10] Canceling priority takeover callback
2021-10-21T06:54:07.210-0400 I ELECTION [replexec-10] Starting an election for a priority takeover
2021-10-21T06:54:07.210-0400 I ELECTION [replexec-10] conducting a dry run election to see if we could be elected. current term: 7
2021-10-21T06:54:07.210-0400 I REPL [replexec-10] Scheduling remote command request for vote request: RemoteCommand 1129 -- target:localhost:27017 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: true, term: 7, candidateIndex: 2, configVersion: 9, lastCommittedOp: { ts: Timestamp(1634813644, 1000), t: 7 } }
2021-10-21T06:54:07.211-0400 I REPL [replexec-10] Scheduling remote command request for vote request: RemoteCommand 1130 -- target:localhost:27018 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: true, term: 7, candidateIndex: 2, configVersion: 9, lastCommittedOp: { ts: Timestamp(1634813644, 1000), t: 7 } }
2021-10-21T06:54:07.211-0400 I ELECTION [replexec-9] VoteRequester(term 7 dry run) received a no vote from localhost:27017 with reason "candidate's data is staler than mine. candidate's last applied OpTime: { ts: Timestamp(1634813644, 1000), t: 7 }, my last applied OpTime: { ts: Timestamp(1634813645, 1000), t: 7 }"; response message: { term: 7, voteGranted: false, reason: "candidate's data is staler than mine. candidate's last applied OpTime: { ts: Timestamp(1634813644, 1000), t: 7 }, my last applied OpTime: { ts: Timest...", ok: 1.0, $clusterTime: { clusterTime: Timestamp(1634813645, 1000), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, operationTime: Timestamp(1634813645, 1000) }
2021-10-21T06:54:07.211-0400 I ELECTION [replexec-2] VoteRequester(term 7 dry run) received a no vote from localhost:27018 with reason "candidate's data is staler than mine. candidate's last applied OpTime: { ts: Timestamp(1634813644, 1000), t: 7 }, my last applied OpTime: { ts: Timestamp(1634813645, 1000), t: 7 }"; response message: { term: 7, voteGranted: false, reason: "candidate's data is staler than mine. candidate's last applied OpTime: { ts: Timestamp(1634813644, 1000), t: 7 }, my last applied OpTime: { ts: Timest...", ok: 1.0, $clusterTime: { clusterTime: Timestamp(1634813645, 1000), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, operationTime: Timestamp(1634813645, 1000) }
2021-10-21T06:54:07.211-0400 I ELECTION [replexec-2] not running for primary, we received insufficient votes
2021-10-21T06:54:07.211-0400 I ELECTION [replexec-2] Lost dry run election
The simulation is successful if we can verify the priority takeover could not complete due to “candidate’s data is staler than mine” failures. This implies the node trying to run for election requested votes from other nodes, which voted “no” as the candidate node needs to catch up. Note that if the oplog of the candidate node is more than 2 seconds behind, the priority takeover will not be scheduled and a failure such as the following will be logged:
2021-10-21T06:55:18.490-0400 I ELECTION [replexec-13] Not starting an election for a priority takeover, since we are not electable due to: Not standing for election because member is not caught up enough to the most up-to-date member to call for priority takeover - must be within 2 seconds (mask 0x80)
Note that this threshold is defined by the priorityTakeoverFreshnessWindowSeconds server parameter which controls how caught up in replication a secondary with higher priority than the current primary must be before it will call for a priority takeover election.
Ensuring Priority Takeover when Lagging
Assuming a 1-2 second delay is consistent, the priority takeover will continually be rescheduled but the election will always fail.
This particular scenario can be overcome using a combination of replSetFreeze and replSetStepDown as follows.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// file: freezeAndStepdown.js
//
function stepDown() {
var host = db.hello().primary;
var client = new Mongo(host)
printjson(client.adminCommand({ replSetStepDown: 30, secondaryCatchUpPeriodSecs: 20 }));
}
function freezeNode(host) {
var client = new Mongo(host)
print("Freezing " + host)
client.adminCommand({ replSetFreeze: 30 })
}
freezeNode("localhost:27017");
freezeNode("localhost:27018");
stepDown();
All other replica set members aside from the one we’ve given the highest priority (localhost:27019 in our scenario) are first frozen to prevent them from seeking election for 30 seconds. The primary is then stepped down with a secondaryCatchUpPeriodSecs of 20 seconds set to allow eligible secondaries to catch up to the primary. As all other nodes are frozen and won’t seek election, the only remaining node which was consistently lagging will catch up and stand for election.
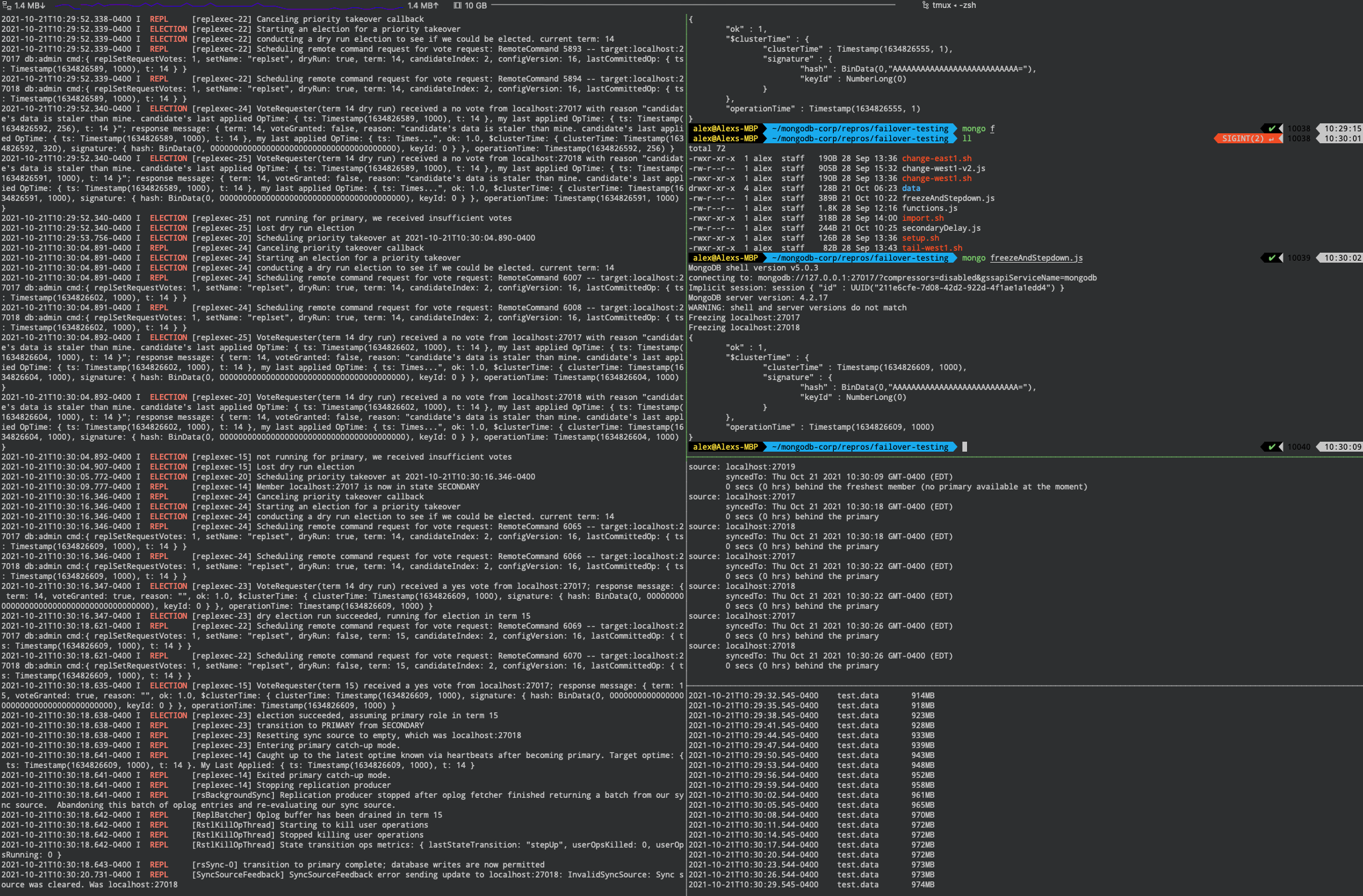
Our previous reproduction using tmux is updated as follows to produce this result:
tail -n 1000 data/replset/rs3/mongod.log | grep -E "(ELECTION|REPL)"mongoimportmongo --quiet secondaryDelay.jsmongo "mongodb://localhost:27017/?replicaset=replset" --quiet --eval "c = rs.conf(); c.members[0].priority = 1; c.members[2].priority = 10; rs.reconfig(c)"mongo --quiet freezeAndStepdown.js
The end result should be the priority takeover attempt resulting in a successful dry run election and subsequent election.
2021-10-21T10:30:04.892-0400 I ELECTION [replexec-15] not running for primary, we received insufficient votes
2021-10-21T10:30:04.907-0400 I ELECTION [replexec-15] Lost dry run election
2021-10-21T10:30:05.772-0400 I ELECTION [replexec-20] Scheduling priority takeover at 2021-10-21T10:30:16.346-0400
2021-10-21T10:30:09.777-0400 I REPL [replexec-14] Member localhost:27017 is now in state SECONDARY
2021-10-21T10:30:16.346-0400 I REPL [replexec-24] Canceling priority takeover callback
2021-10-21T10:30:16.346-0400 I ELECTION [replexec-24] Starting an election for a priority takeover
2021-10-21T10:30:16.346-0400 I ELECTION [replexec-24] conducting a dry run election to see if we could be elected. current term: 14
2021-10-21T10:30:16.346-0400 I REPL [replexec-24] Scheduling remote command request for vote request: RemoteCommand 6065 -- target:localhost:27017 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: true, term: 14, candidateIndex: 2, configVersion: 16, lastCommittedOp: { ts: Timestamp(1634826609, 1000), t: 14 } }
2021-10-21T10:30:16.346-0400 I REPL [replexec-24] Scheduling remote command request for vote request: RemoteCommand 6066 -- target:localhost:27018 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: true, term: 14, candidateIndex: 2, configVersion: 16, lastCommittedOp: { ts: Timestamp(1634826609, 1000), t: 14 } }
2021-10-21T10:30:16.347-0400 I ELECTION [replexec-23] VoteRequester(term 14 dry run) received a yes vote from localhost:27017; response message: { term: 14, voteGranted: true, reason: "", ok: 1.0, $clusterTime: { clusterTime: Timestamp(1634826609, 1000), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, operationTime: Timestamp(1634826609, 1000) }
2021-10-21T10:30:16.347-0400 I ELECTION [replexec-23] dry election run succeeded, running for election in term 15
2021-10-21T10:30:18.621-0400 I REPL [replexec-22] Scheduling remote command request for vote request: RemoteCommand 6069 -- target:localhost:27017 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: false, term: 15, candidateIndex: 2, configVersion: 16, lastCommittedOp: { ts: Timestamp(1634826609, 1000), t: 14 } }
2021-10-21T10:30:18.621-0400 I REPL [replexec-22] Scheduling remote command request for vote request: RemoteCommand 6070 -- target:localhost:27018 db:admin cmd:{ replSetRequestVotes: 1, setName: "replset", dryRun: false, term: 15, candidateIndex: 2, configVersion: 16, lastCommittedOp: { ts: Timestamp(1634826609, 1000), t: 14 } }
2021-10-21T10:30:18.635-0400 I ELECTION [replexec-15] VoteRequester(term 15) received a yes vote from localhost:27017; response message: { term: 15, voteGranted: true, reason: "", ok: 1.0, $clusterTime: { clusterTime: Timestamp(1634826609, 1000), signature: { hash: BinData(0, 0000000000000000000000000000000000000000), keyId: 0 } }, operationTime: Timestamp(1634826609, 1000) }
2021-10-21T10:30:18.638-0400 I ELECTION [replexec-23] election succeeded, assuming primary role in term 15
2021-10-21T10:30:18.638-0400 I REPL [replexec-23] transition to PRIMARY from SECONDARY
From the screenshots we can see that during all election attempts the mongoimport workload continued to operate without issue.
Did this article help you? Let me know in the comments below ;)
Comments powered by Disqus.