Live Migration of Sharded Clusters to MongoDB Atlas could result in TooManyLogicalSessions Errors
The following is more of a diagnostic journey than anything else, and does not reflect a current issue with MongoDB Atlas.
While I was still working as a Technical Services Engineer at MongoDB in 2021 a small number of customers were reporting that their applications would start throwing errors similar to the following after upgrading from MongoDB 3.6 to 4.0:
Command failed with error 261: 'cannot add session into the cache' on server xxx.yyy.zzz.com:27017. The full response is { "ok" : 0.0, "errmsg" : "cannot add session into the cache", "code" : 261, "codeName" : "TooManyLogicalSessions" }
When this error would occur, no further operations could be run against that shard until the mongod process was restarted. Clusters would not immediately exceed their logical session limit and it could take days or weeks for some clusters to reach this failure condition depending on their level of activity.
After much investigation the issue boiled down to a confluence of the following scenarios:
- A Sharded Cluster was Live Migrated to MongoDB Atlas
- The original sharded cluster (correctly) had more than 1 chunk associated with the
config.system.sessionscollection - When Live Migrate was finalizing, the
config.system.sessionsentry was removed fromconfig.collectionsbut only one (of many) chunks were removed fromconfig.chunks
… but why?
Technical Details
To provide causal consistency, MongoDB 3.6 introduced client sessions. The underlying framework used by client sessions to support causal consistency (as well as retryable writes) are server sessions.
Per the Driver Sessions Specification, starting with MongoDB 3.6, MongoDB Drivers associate all operations with a server session (with the exception of unacknowledged writes). The logic defined in this spec regarding “How to Check Whether a Deployment Supports Sessions” states that:
- If the
TopologyDescriptionand connection type indicate that- the driver is not connected to any servers, OR
- is not a direct connection AND is not connected to a data-bearing server then a driver must do a server selection for any server whose type is data-bearing. Server selection will either time out or result in a
TopologyDescriptionthat includes at least one connected, data-bearing server.
- Having verified in step 1 that the
TopologyDescriptionincludes at least one connected server a driver can now determine whether sessions are supported by inspecting theTopologyTypeandlogicalSessionTimeoutMinutesproperty.
With MongoDB 3.6, the hello command when targeting a sharded cluster will only return the logicalSessionTimeoutMinutes under two conditions:
- (Starting with MongoDB 3.6.0 via SERVER-31777) When the
featureCompatibilityVersionis set to “3.6” AND - (Starting with MongoDB 3.6.9 via SERVER-37631) The cluster has a valid
system.sessionscollection
Starting in MongoDB 4.0, an hello command when targeting a sharded cluster will always return logicalSessionTimeoutMinutes, as the featureCompatibilityVersion test has been removed (via SERVER-32460). The test for a valid system.sessions collections was not included in MongoDB 4.0.
As a result, if the cluster contains a “broken” system.sessions collection the following can occur:
- On MongoDB 3.6,
hellodoesn’t returnlogicalSessionTimeoutMinuteswhich causes the driver to determine that sessions are not supported on this cluster, resulting in logical sessions not being used - On MongoDB 4.0,
helloalways returnslogicalSessionTimeoutMinutes, resulting in the driver enabling logical sessions. If a “broken”system.sessionscollection exists, the sessions are not persisted/expired properly which can result in cluster failure once themaxSessionsthreshold (default: 1,000,000) is reached.
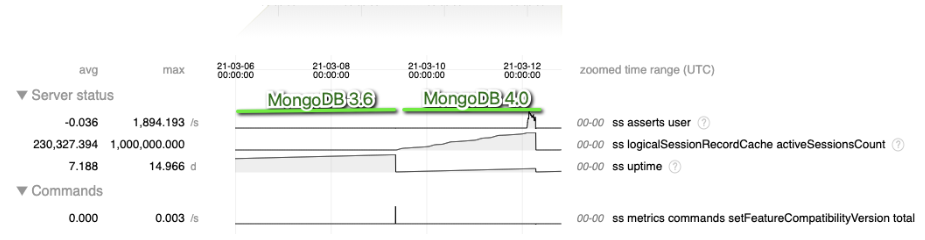 Screenshot from a tool used to chart FTDC telemetry
Screenshot from a tool used to chart FTDC telemetry
What is the system.sessions collection
The system.sessions collection stores session records that are available to all members of the deployment.
When a user creates a session on a mongod or mongos instance, the record of the session initially exists only in-memory on the instance. Periodically, the instance will sync its cached sessions to the system.sessions collection; at which time, they are visible to all members of the deployment.
In a sharded cluster, the system.sessions collection is sharded. When adding a shard to the sharded cluster, if the shard to add already contains its own system.sessions collection, MongoDB drops the new shard’s system.sessions collection during the add process.
What is a “broken” system.sessions collection
The system.sessions collection is expected to be sharded, however in some cases, the system.sessions collection may be mistakenly created on the Config Servers as an unsharded collection. Each sharded node in a cluster expects to be able to write documents to the sessions collection, which is why it is necessary for the sessions collection to be sharded.
When the system.sessions collection is “broken” the LogicalSessionCache* threads will emit log messages such as the following:
1
2
3
4
5
6
// Primary Shard Logs
2021-03-12T19:32:51.551+0000 I CONTROL [LogicalSessionCacheRefresh] Sessions collection is not set up; waiting until next sessions refresh interval: Collection config.system.sessions is not sharded.
2021-03-12T19:32:51.556+0000 I CONTROL [LogicalSessionCacheReap] Sessions collection is not set up; waiting until next sessions reap interval: Collection config.system.sessions is not sharded.
// Config Server Logs
2021-03-12T18:32:31.725+0000 I CONTROL [LogicalSessionCacheRefresh] Failed to create config.system.sessions: Not primary while running findAndModify command on collection config.locks, will try again at the next refresh interval
How does the system.sessions collection “break” in Atlas
At the time of investigation the working hypothesis was that there was a defect associated with the Live Migration process for Sharded Clusters. When the Live Migration tool was run the following was observed:
- When the
config.system.sessionscollection is migrated it is not initially sharded - There are, however chunks associated with the
config.system.sessionscollection - Reviewing the
oplogfor the Config Server replica set shows an entry where the config.system.sessionscollection is removed from theconfig.collectionscollection along with an entry in theconfig.chunkscollection:1 2
{ "ts" : Timestamp(1616135732, 11), "t" : NumberLong(2), "h" : NumberLong("-2957928371374723467"), "v" : 2, "op" : "d", "ns" : "config.chunks", "ui" : UUID("933eed1e-f9a6-4ad7-93e5-f799e0d41484"), "wall" : ISODate("2021-03-19T06:35:32.598Z"), "o" : { "_id" : "config.`system.sessions`-_id_MinKey" } } { "ts" : Timestamp(1616135732, 12), "t" : NumberLong(2), "h" : NumberLong("7339349496984671905"), "v" : 2, "op" : "d", "ns" : "config.collections", "ui" : UUID("703ea46b-44c6-435c-8dc3-91f9cf287c08"), "wall" : ISODate("2021-03-19T06:35:32.607Z"), "o" : { "_id" : "config.`system.sessions`" } }
Based on this observation it appeared that during the live migration’s temporary data/metadata cleanup process (for a sharded cluster), the config.system.sessions collection was being removed from the config.collections collection which makes it appear to the cluster that config.system.sessions is unsharded.
The LogicalSessionCacheRefresh thread should automatically recreate the collection as sharded in this case, however as there are still chunks associated with the collection this process failed and was retried indefinitely.
Identification & Mitigation
Any sharded cluster can be tested for an incorrectly (“broken”) configured config.system.sessions collection (caused by the suspected deficiency in Live Migrate or otherwise) by connecting (via the mongo or mongosh shell) and running:
1
db.getSiblingDB('config').system.sessions.stats()['sharded']
If the result of the above command is NOT true (either false or blank), performing the following actions on the cluster would address the issue:
1
2
3
// Connect to the PRIMARY member of CSRS and ALL Shard PRIMARY members
// and run the following command
db.system.sessions.drop();
1
2
3
// Connect to a single mongos configured for your cluster and run the following
db.getSiblingDB('config').chunks.remove( {ns:'config.system.sessions'})
db.adminCommand("flushRouterConfig")
Hopefully you’ll never find yourself in a situation such as the one described above, but if you do this guide may be useful for getting your cluster back up and running.
Comments powered by Disqus.