Retryable Writes, findAndModify and the impact on the MongoDB Oplog

When you’re monitoring your cluster using Ops Manager or MongoDB Atlas and the Replication Oplog Window is (X) drastically drops, what can you do?
Having a very short operations log (oplog) window increases the likelihood that a SECONDARY member can fall off the oplog and require a full resync, however if the window remains small the resync may fail as the oplog window must be larger than the time needed to resync.
One scenario that can result in the oplog window shrinking is the use of findAndModify operations when retryable writes are enabled, but how do we identify that they are the culprit?
Overview
MongoDB introduced Retryable Writes in 3.6 as a way to allow Drivers (that have implemented the Retryable Write specification) a mechanism to retry certain write operations a single time if they encounter network errors, or if they cannot find a healthy primary in the replica sets or sharded cluster.
When the findAndModify command was made retryable (via SERVER-30407), the implementation involved writing an additional no-op to the oplog that would contain a pre (or post) image of an update (or delete) operation.
Prior to MongoDB 4.4, the oplog size was configured in megabytes. As it is a capped collection, once the configured size was filled the oldest entries were removed as new entries were written.
With MongoDB 4.4 an option was added to configure a minimum oplog retention period (in hours), however this is not presently the default behavior when configuring a replica set.
In this article we’ll be exploring the impact of retryable findAndModify operations on a local MongoDB 5.0.2 replica set running a Ruby script (see Appendix).
Retryable Writes enabled
With the series of MongoDB Drivers that support MongoDB 4.2 Retryable Writes are enabled by default, however setting the retryWrites URI option can still be used to explicitly toggle this feature.
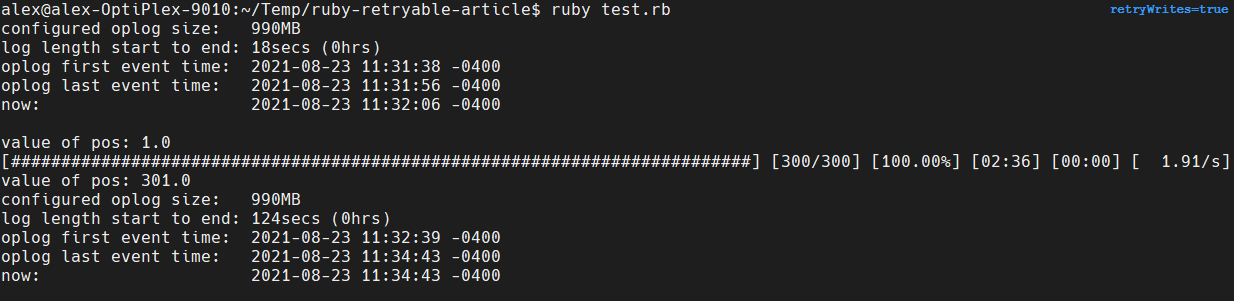
When the script is run for the first time it will update the document configured during setup (see Appendix) and increment a value 300 times.
Before the script runs the first event time (in the oplog) is 2021-08-23 11:31:38. After the script runs, the first event time is 2021-08-23 11:32:39. As our oplog is configured at 990MB this would imply MORE than 990MB were written as the oldest events appear to start after the script began.
As a result, the oplog has fully churned during the course of this script running.
The sample document we’re incrementing a value on is 5MB, and if we’re running 300 updates approximately 1.5GB of uncompressed would have been written to the oplog.
Retryable Writes disabled

For this test run the application was modified to disable retryWrites from the connection string:
1
2
3
# ...
client = Mongo::Client.new("mongodb://localhost:27017/?retryWrites=false")
# ...
As retryable writes are disabled there is no pre/post-image data being written to the oplog. This can be seen in the first event times being the same before and after the script runs (2021-08-23 11:32:39).
NOTE: For Atlas clusters where setParameter is an Unsupported Command, disabling retryable writes or refactoring the findAndModify to instead perform a find followed by an update would be the best paths forward.
Server Parameters and Retryable Writes
As a result of the impact on the oplog when using findAndModify, SERVER-56372 was created to allow the pre/post-image storage to be moved to a non-oplog collection.
This functionality is available in MongoDB 5.0+, and was backported to MongoDB 4.4.7 and MongoDB 4.2.16.
To enable this functionality an additional Server Parameter must be enabled at startup using the setParameter command as follows:
1
2
mongod <.. other options ..> \
--setParameter storeFindAndModifyImagesInSideCollection=true
An additional
setParameteroffeatureFlagRetryableFindAndModify=truewas required to test this feature prior to MongodB 4.4.7/4.2.16
This parameter would need to be set on each mongod node in the cluster. By doing this the pre/post-images will instead be saved to the config.image_collection namespace.
storeFindAndModifyImagesInSideCollectionis enabled by default starting in MongoDB 5.1
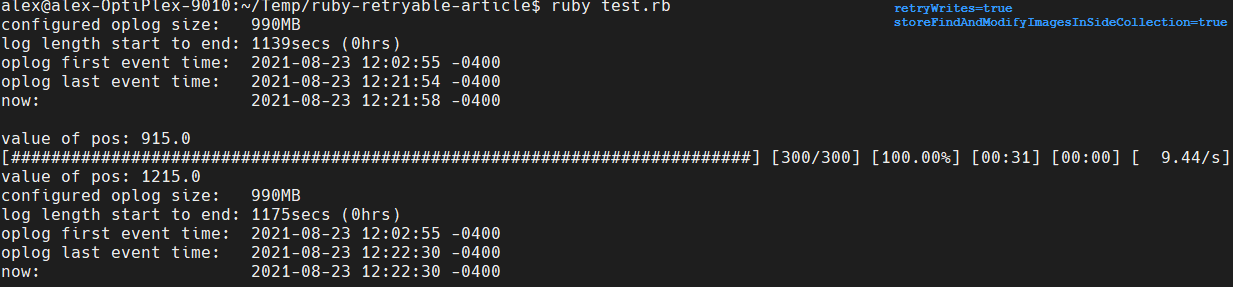
When the script is run now with retryable writes enabled, the impact on the oplog should be as negligible as it was when retryWrites=false was set previously.
For those that are curious, the config.image_collection namespace contains documents such as the following:
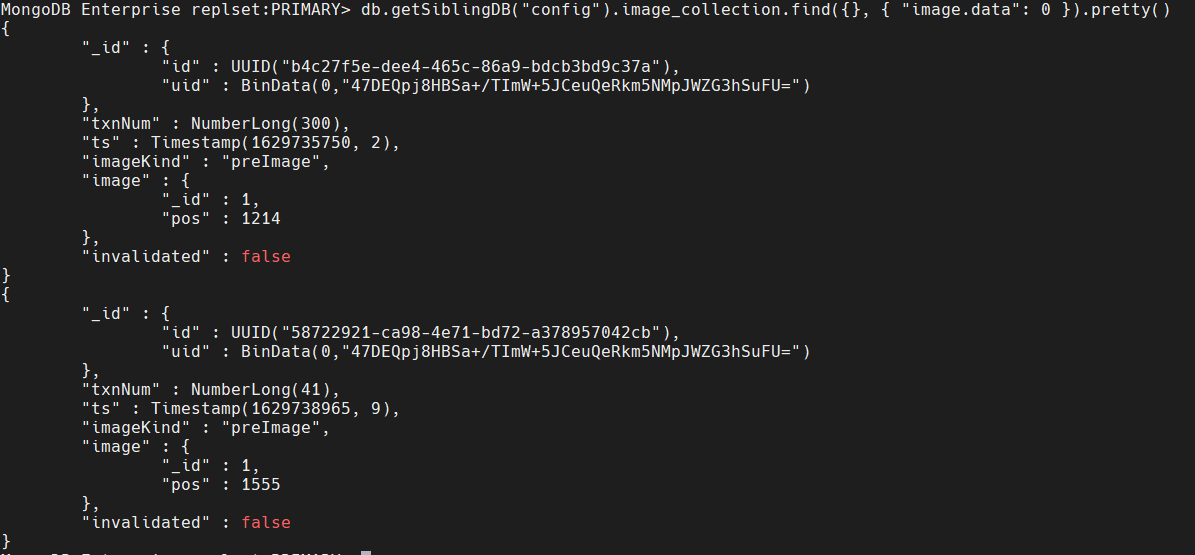
(Due to the size of the data field it’s been projected out)
Conclusion
If your applications are using findAndModify heavily and your cluster’s oplog is churning, there are a number of options to consider:
- Disable retryable writes (
retryWrites=falsein the connection string) - Split the
findAndModifyoperations intofindandupdateoperations - Configure
featureFlagRetryableFindAndModifyandstoreFindAndModifyImagesInSideCollection(assuming your version of MongoDB is 4.2.15+, 4.4.7+ or 5.0+)
Let me know if you found this article useful in the comments below.
Happy Coding!
Appendix
The test script and steps to configure a local cluster are below if you want to validate the findings in this article yourself.
Setup
We’ll be using m and mtools to setup the cluster, along with a Javascript script to automate configuration.
1
2
3
4
5
6
# download and install MongoDB 5.0.2 enterprise
m 5.0.2-ent
# initialize a 3 node replicaset using MongoDB 5.0.2
mlaunch init --replicaset --nodes 3 --binarypath $(m bin 5.0.2-ent)
# wait about 30 seconds before running the script
mongo setup.js
The contents of the setup.js script above are:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
function generate_random_data(size){
var chars = 'abcdefghijklmnopqrstuvwxyz'.split('');
var len = chars.length;
var random_data = [];
while (size--) { random_data.push(chars[Math.random()*len | 0]); }
return random_data.join('');
}
function setup() {
// setup oplog with the minimum size of 990MB
db.adminCommand({ replSetResizeOplog: 1, size: 990 })
db.foo.drop();
// setup 1 document with 5MB of junk data
db.foo.insertOne({ _id: 1, pos: 1, data: generate_random_data(5 * 1024 * 1024) })
}
setup();
The test.foo namespace is being setup with a single document that contains 5MB of junk data and a pos field we’ll be incrementing via the script below.
Test Script
We’ll be using a standalone Ruby script that uses the latest MongoDB Ruby Driver (version 2.15 at time of writing).
At a high level, the script does the following:
- Connect to the cluster
- Print replication info
- Using
findAndModifyincrement (via$inc) a value 300 times - Print replication info again
This script (see below) can be executed as follows:
1
ruby test.rb
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# !/usr/bin/env ruby
#
# filename: test.rb
#
require "bundler/inline"
gemfile do
source "https://rubygems.org"
gem "mongo"
gem "progress_bar"
end
def get_seconds(ts)
(ts.seconds && ts.increment) ? ts.seconds : ts / 4294967296 # low 32 bits are ordinal #s within a second
end
def get_replication_info(client)
db = client.use(:local).database
olStats = db.command({ collStats: "oplog.rs" }).documents.first
logSizeMB = olStats["maxSize"] / (1024 * 1024)
usedMB = olStats["size"] / (1024 * 1024)
coll = db["oplog.rs"]
first = coll.find.sort("$natural": 1).first
last = coll.find.sort("$natural": -1).first
tfirst = get_seconds(first["ts"])
tlast = get_seconds(last["ts"])
timeDiff = tlast - tfirst
timeDiffHours = ((timeDiff / 36) / 100).round
puts "configured oplog size: #{logSizeMB}MB\n"
puts "log length start to end: #{timeDiff}secs (#{timeDiffHours}hrs)\n"
puts "oplog first event time: #{Time.at(tfirst)}\n"
puts "oplog last event time: #{Time.at(tlast)}\n"
puts "now: #{Time.now}\n"
end
def update_docs_with_junk(coll)
coll.find_one_and_update({ _id: 1 }, { "$inc": { pos: 1 } })
end
def print_field_value(coll)
v = coll.find(_id: 1).first["pos"]
puts "value of pos: #{v}\n"
end
client = Mongo::Client.new("mongodb://localhost:27017/?retryWrites=true")
puts get_replication_info(client)
coll = client.use(:test).database[:foo]
print_field_value(coll)
max = 300
pb = ProgressBar.new(max)
max.times do
pb.increment!
update_docs_with_junk(coll)
end
print_field_value(coll)
puts get_replication_info(client)
Comments powered by Disqus.